Let me begin with - Happy New Year! I am starting this years BLOG entry with some playing I did over the holidays with Apache ZooKeeper. So what is Apache ZooKeeper? Broadly put, ZooKeeper provides a service for maintaining distributed naming, configuration and group membership. Zookeeper provides a centralized coordination service which is distributed, consistent and highly available. In particular, it specializes in coordination tasks such as leader election, status propagation and rendezvous. Quoting the ZooKeeper documentation, " The
motivation behind ZooKeeper is to relieve distributed applications the
responsibility of implementing coordination services from scratch."
Zookeeper facilitates the coordination of distributed systems via a hierarchical name space called ZNodes. A ZNode can have children Znodes as well as have data associated with it (figure linked from official ZooKeeper documentation):

ZooKeeper also has the concept of Nodes and Ephermeral Nodes. The former survives the death of the client that created it while the latter does not. Nodes can also be SEQUENTIAL where a SEQUENCE number is associated with Node. Sequences clearly lend themselves for queue type or ordered behavior when required. ZNodes cannot be deleted as long as they have children under it.
The Zookeeper API itself it a very simple programming interface that contains methods for CRUD of a ZNode and data along with a way to listen for changes to the node and/or its data.
One can read quite a bit about Zookeeper from their documentation and I will not delve into details. My goal in this BLOG is to provide some simple examples of how Zookeeper can be used for:
1. Leader Election
2. Rendezvous or Barrier
1. Leader Election Example:
As mentioned previously, Zoo Keeper specializes in Leader Election, where a particular server of a type is elected the leader and upon its demise, another stands up to take its place. The concept of Ephemeral nodes is pretty useful in such a scenario where a service upon start up registers itself as a candidate in the pool of resources to be used. For the sake of discussion, consider an Echo Service with the fictional constraint that there can be only one Echo Service at any given time servicing requests but should that robust service die, another one is ready to resume the responsibility of servicing clients. The EchoService on start up registers an ephemeral node at "/echo/n_000000000X". It further registers a watcher on its predecessor Echo Service, denoted by the ZNode, "/echo/n_000000000X-1", with the intent that should the predecessor die, then the node in question can assume leadership if it is the logical successor as shown in the picture below:
The reason for registering a watch on the predecessor versus the root of "/echo" is to prevent herding as described in the Zookeeper recipes. In other words in the event of a leader being decommisioned, we wouldn't want all the Echo Server leadership contenders to stress the system by requesting ZooKepper for the children of the "/echo" node to determine the next leader. With the chosen strategy, if the predecessor dies, then only its follower is the one that executes the call to get the children of "/echo". The example provided herewith spawns two Echo Servers and has a client that calls the server. One of the two servers is considered the leader and assumes the responsibility of servicing the requests of the client. If the leader dies, then the successor Echo Server assumes leadership and starts servicing client requests. The client will connect to the next leader automatically upon the death of the current leader. The Echo Server code is shown below:
The Echo Client is shown below which connects to the leader of the Echo Server ensemble:
A simple test of the example starts an EchoClient and two servers. One of the servers assumes leadership and starts servicing request while the other server sits waiting to assume leadership. The client in turn sends messages which is serviced by the leader. When the leader terminates, messages are then serviced by the successor that assumes leadership.
2. Rendezvous/Barrier Example:
Distributed systems can use the concept of a barrier to block the processing of a certain task until other members of the system ensemble are available after which all the systems participating can proceed with their tasks. Having a little fun here :-) with a fictional case where Double O agents of MI-6 meet to present their reports, and reports are not edited here if you know what I mean ;-). Agents join the meeting but cannot start presenting until all the expected agents join the meeting after which they are free to present in parallel (agents are designed to grasp from multiple presenters; after all the 007 variety are trained at such things). Agents can present but cannot leave the briefing until all presenters have completed their presentation. The agent upon start up creates a ZNode under the meeting identifier, say, "/M-debrief", and then waits for all other agents to join before beginning their presentation, i.e., barrier entry. After each presentation, the agent removes themselves from the list of ZNodes and then waits for other agents to do the same before leaving the briefing, i.e., barrier exit. With that said, the Agent code looks like:
Running the code:
Download a maven example of the above code from HERE. Execute a "mvn test" to see the example in action or import into eclipse to dissect the code. The example itself runs its tests on a single ZooKeeper server. There is no reason why the same cannot be expanded to try on a larger ZooKeeper ensemble.
Conclusion and Credits:
The examples shown are highly influenced by the examples provided at the ZooKeeper site. The code does not use the ZooKeeper code directly but instead uses a wrapper around the same, i.e., ZkClient, which provides a much easier experience to using ZooKeeper than the default ZooKeeper API. The examples also rely heavily on the excellent article and supporting code by Erez Mazor who utilizes Spring Framework very nicely to demonstrate Leader Election and control of the same. I simply loved his code and images and have used parts of the same in the above demonstration. I am sure I have only touched the surface of ZooKeeper and am hoping I can learn more about the same. If my understanding about any of the concepts mentioned above is flawed, I would love to hear about the same. Again, a very Happy 2012! Keep the faith, the world won't end on December 21'st.
Zookeeper facilitates the coordination of distributed systems via a hierarchical name space called ZNodes. A ZNode can have children Znodes as well as have data associated with it (figure linked from official ZooKeeper documentation):
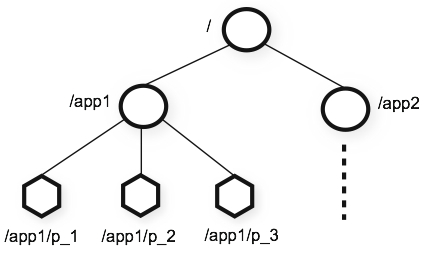
ZooKeeper also has the concept of Nodes and Ephermeral Nodes. The former survives the death of the client that created it while the latter does not. Nodes can also be SEQUENTIAL where a SEQUENCE number is associated with Node. Sequences clearly lend themselves for queue type or ordered behavior when required. ZNodes cannot be deleted as long as they have children under it.
The Zookeeper API itself it a very simple programming interface that contains methods for CRUD of a ZNode and data along with a way to listen for changes to the node and/or its data.
One can read quite a bit about Zookeeper from their documentation and I will not delve into details. My goal in this BLOG is to provide some simple examples of how Zookeeper can be used for:
1. Leader Election
2. Rendezvous or Barrier
1. Leader Election Example:
As mentioned previously, Zoo Keeper specializes in Leader Election, where a particular server of a type is elected the leader and upon its demise, another stands up to take its place. The concept of Ephemeral nodes is pretty useful in such a scenario where a service upon start up registers itself as a candidate in the pool of resources to be used. For the sake of discussion, consider an Echo Service with the fictional constraint that there can be only one Echo Service at any given time servicing requests but should that robust service die, another one is ready to resume the responsibility of servicing clients. The EchoService on start up registers an ephemeral node at "/echo/n_000000000X". It further registers a watcher on its predecessor Echo Service, denoted by the ZNode, "/echo/n_000000000X-1", with the intent that should the predecessor die, then the node in question can assume leadership if it is the logical successor as shown in the picture below:
 |
| Leader Election of Echo Server |
The reason for registering a watch on the predecessor versus the root of "/echo" is to prevent herding as described in the Zookeeper recipes. In other words in the event of a leader being decommisioned, we wouldn't want all the Echo Server leadership contenders to stress the system by requesting ZooKepper for the children of the "/echo" node to determine the next leader. With the chosen strategy, if the predecessor dies, then only its follower is the one that executes the call to get the children of "/echo". The example provided herewith spawns two Echo Servers and has a client that calls the server. One of the two servers is considered the leader and assumes the responsibility of servicing the requests of the client. If the leader dies, then the successor Echo Server assumes leadership and starts servicing client requests. The client will connect to the next leader automatically upon the death of the current leader. The Echo Server code is shown below:
public class EchoServer extends Thread implements IZkDataListener, IZkStateListener {
private ZkClient zkClient;
// My ZNode
private SequentialZkNode zkNode;
// My leader ZNode
private SequentialZkNode zkLeaderNode;
private ServerSocket serverSocket;
// Port to start server on
private final Integer port;
private final List<SlaveJob> slaves;
private final Object mutex = new Object();
private final AtomicBoolean start = new AtomicBoolean(false);
private final Random random = new Random();
public EchoServer(int port, int zkPort) {
this.port = port;
this.zkClient = new ZkClient("localhost:" + zkPort);
this.slaves = new ArrayList<SlaveJob>();
}
@Override
public void run() {
try {
// Sleep for some randomness leader selection
Thread.sleep(random.nextInt(1000));
// Create Ephermal node
zkNode = ZkUtils.createEphermalNode("/echo", port, zkClient);
// Find all children
NavigableSet<SequentialZkNode> nodes = ZkUtils.getNodes("/echo", zkClient);
// Find my leader
zkLeaderNode = ZkUtils.findLeaderOfNode(nodes, zkNode);
// If I am leader, enable me to start
if (zkLeaderNode.getPath().equals(zkNode.getPath())) {
start.set(true);
} else {
// Set a watch on next leader path
zkClient.subscribeDataChanges(zkLeaderNode.getPath(), this);
zkClient.subscribeStateChanges(this);
}
synchronized (mutex) {
while (!start.get()) {
LOG.info("Server on Port:" + port + " waiting to spawn socket....");
mutex.wait();
}
}
// Start accepting connections and servicing requests
this.serverSocket = new ServerSocket(port);
Socket clientSocket = null;
while (!Thread.currentThread().isInterrupted() && !shutdown) {
clientSocket = serverSocket.accept();
// ... start slave job
}
}
catch (Exception e) {
....
}
}
private void electNewLeader() {
final NavigableSet<SequentialZkNode> nodes = ZkUtils.getNodes("/echo", zkClient);
if (!zkClient.exists(zkLeaderNode.getPath())) {
// My Leader does not exist, find the next leader above
zkLeaderNode = ZkUtils.findLeaderOfNode(nodes, zkNode);
zkClient.subscribeDataChanges(zkLeaderNode.getPath(), this);
zkClient.subscribeStateChanges(this);
}
// If I am the leader then start
if (zkNode.getSequence().equals(nodes.first().getSequence())) {
LOG.info("Server on port:" + port + " will now be notified to assume leadership");
synchronized (mutex) {
start.set(true);
mutex.notify();
}
}
}
.....
@Override
public void handleDataDeleted(String dataPath) throws Exception {
if (dataPath.equals(zkLeaderNode.getPath())) {
// Leader gone away
LOG.info("Recieved a notification that Leader on path:" + dataPath
+ " has gone away..electing new leader");
electNewLeader();
}
}
}
The Echo Client is shown below which connects to the leader of the Echo Server ensemble:
public class EchoClient implements IZkDataListener, IZkStateListener, IZkChildListener {
private Connection connection;
private Object mutex = new Object();
private final ZkClient zkClient;
private SequentialZkNode connectedToNode;
public EchoClient(int zkPort) {
this.zkClient = new ZkClient("localhost:" + zkPort);
}
private Connection getConnection() throws UnknownHostException, IOException, InterruptedException {
synchronized (mutex) {
if (connection != null) {
return connection;
}
NavigableSet<SequentialZkNode> nodes = null;
// Check to see if there an Echo server exists, if not listen on /echo for
// a Server to become available
while ((nodes = ZkUtils.getNodes("/echo", zkClient)).size() == 0) {
LOG.info("No echo service nodes ...waiting...");
zkClient.subscribeChildChanges("/echo", this);
mutex.wait();
}
// Get the leader and connect
connectedToNode = nodes.first();
Integer port = zkClient.readData(connectedToNode.getPath());
connection = new Connection(new Socket("localhost", port));
// Subscribe to Server changes
zkClient.subscribeDataChanges(connectedToNode.getPath(), this);
zkClient.subscribeStateChanges(this);
}
return connection;
}
public String echo(String command) throws InterruptedException {
while (true) {
try {
return getConnection().send(command);
}
catch (InterruptedException e) {
throw e;
}
catch (Exception e) {
synchronized (mutex) {
if (connection != null) {
connection.close();
connection = null;
}
}
}
}
}
private static class Connection {
// Code that connects and sends data to Echo Server
public String send(String message) {
....
}
}
@Override
public void handleDataDeleted(String dataPath) throws Exception {
synchronized (mutex) {
if (dataPath.equals(connectedToNode.getPath())) {
LOG.info("Client Received notification that Server has died..notifying to re-connect");
if (connection != null) {
connection.close();
}
if (connectedToNode != null) {
connectedToNode = null;
}
}
mutex.notify();
}
}
@Override
public void handleChildChange(String parentPath, List<String> currentChilds) throws Exception {
synchronized (mutex) {
LOG.info("Got a notification about a Service coming up...notifying client");
mutex.notify();
}
}
}
A simple test of the example starts an EchoClient and two servers. One of the servers assumes leadership and starts servicing request while the other server sits waiting to assume leadership. The client in turn sends messages which is serviced by the leader. When the leader terminates, messages are then serviced by the successor that assumes leadership.
@Test
public void simpleLeadership() throws InterruptedException {
EchoClient client = new EchoClient(ZK_PORT);
EchoServer serverA = new EchoServer(5555, ZK_PORT);
EchoServer serverB = new EchoServer(5556, ZK_PORT);
serverA.start();
serverB.start();
// Send messages
for (int i = 0; i < 10; i++) {
System.out.println("Client Sending:Hello-" + i);
System.out.println(client.echo("Hello-" + i));
}
if (serverA.isLeader()) {
serverA.shutdown();
} else {
serverB.shutdown();
}
for (int i = 0; i < 10; i++) {
System.out.println("Client Sending:Hello-" + i);
System.out.println(client.echo("Hello-" + i));
}
serverA.shutdown();
serverB.shutdown();
}
On running the test, you can see output similar to:
20:18:49 INFO - com.welflex.zookeeper.EchoClient.getConnection(44) | No echo service nodes ...waiting... 20:18:49 INFO - com.welflex.zookeeper.EchoClient.handleChildChange(171) | Got a notification about a Service coming up...notifying client 20:18:49 INFO - com.welflex.zookeeper.EchoServer.run(85) | Server on Port:5556 is now the Leader. Starting to accept connections... Client Sending:Hello-0 Echo:Hello-0 Client Sending:Hello-1 Echo:Hello-1 ..... 20:18:49 INFO - com.welflex.zookeeper.EchoServer.run(122) | Server on Port:5556 has been shutdown 20:18:49 INFO - com.welflex.zookeeper.EchoClient.getConnection(44) | No echo service nodes ...waiting... Server has died..notifying to re-connect 20:18:49 INFO - com.welflex.zookeeper.EchoClient.getConnection(44) | No echo service nodes ...waiting... 20:18:49 INFO - com.welflex.zookeeper.EchoClient.handleChildChange(171) | Got a notification about a Service coming up...notifying client 20:18:49 INFO - com.welflex.zookeeper.EchoServer.run(85) | Server on Port:5555 is now the Leader. Starting to accept connections... 20:18:49 INFO - com.welflex.zookeeper.EchoClient.handleChildChange(171) | Got a notification about a Service coming up...notifying client .... Echo:Hello-7 Client Sending:Hello-8 Echo:Hello-8 Client Sending:Hello-9 Echo:Hello-9 ....
2. Rendezvous/Barrier Example:
Distributed systems can use the concept of a barrier to block the processing of a certain task until other members of the system ensemble are available after which all the systems participating can proceed with their tasks. Having a little fun here :-) with a fictional case where Double O agents of MI-6 meet to present their reports, and reports are not edited here if you know what I mean ;-). Agents join the meeting but cannot start presenting until all the expected agents join the meeting after which they are free to present in parallel (agents are designed to grasp from multiple presenters; after all the 007 variety are trained at such things). Agents can present but cannot leave the briefing until all presenters have completed their presentation. The agent upon start up creates a ZNode under the meeting identifier, say, "/M-debrief", and then waits for all other agents to join before beginning their presentation, i.e., barrier entry. After each presentation, the agent removes themselves from the list of ZNodes and then waits for other agents to do the same before leaving the briefing, i.e., barrier exit. With that said, the Agent code looks like:
public class Agent extends Thread implements IZkChildListener {
// Number of agents total
private final int agentCount;
private final String agentNumber;
private final Object mutex = new Object();
private final Random random = new Random();
private SequentialZkNode agentRegistration;
private final String meetingId;
public Agent(String agentNumber, String meetingId, int agentCount, int zkPort) {
this.agentNumber = agentNumber;
this.meetingId = meetingId;
this.agentCount = agentCount;
this.zkClient = new ZkClient("localhost:" + zkPort);
zkClient.subscribeChildChanges(meetingId, this);
}
private void joinBriefing() throws InterruptedException {
Thread.sleep(random.nextInt(1000));
agentRegistration = ZkUtils.createEpheremalNode(meetingId, agentNumber, zkClient);
LOG.info("Agent:" + agentNumber + " joined Briefing:" + meetingId);
// Wait for all other agents to join the meeting
while (true) {
synchronized (mutex) {
List<String> list = zkClient.getChildren(meetingId);
if (list.size() < agentCount) {
LOG.info("Agent:" + agentNumber + " waiting for other agents to join before presenting report...");
mutex.wait();
}
else {
break;
}
}
}
}
private void presentReport() throws InterruptedException {
LOG.info("Agent:" + agentNumber + " presenting report...");
Thread.sleep(random.nextInt(1000));
LOG.info("Agent:" + agentNumber + " completed report...");
// Completion of a report is identified by deleting their ZNode
zkClient.delete(agentRegistration.getPath());
}
private void leaveBriefing() throws InterruptedException {
// Wait for all agents to complete
while (true) {
synchronized (mutex) {
List<String> list = zkClient.getChildren(meetingId);
if (list.size() > 0) {
LOG.info("Agent:" + agentNumber
+ " waiting for other agents to complete their briefings...");
mutex.wait();
}
else {
break;
}
}
}
LOG.info("Agent:" + agentNumber + " left briefing");
}
@Override
public void run() {
joinBriefing();
presentReport();
leaveBriefing();
}
@Override
public void handleChildChange(String parentPath, List<String> currentChilds) throws Exception {
synchronized (mutex) {
mutex.notifyAll();
}
}
}
Running the test, one would see something like the following where agents join the meeting, wait for the others before presenting, present at the meeting and then leave after everyone completes. Note that output is edited in the interest of real estate:
21:02:17 INFO - com.welflex.zookeeper.Agent.joinBriefing(38) | Agent:003 joined Briefing:/M-debrief 21:02:17 INFO - com.welflex.zookeeper.Agent.joinBriefing(45) | Agent:003 waiting for other agents to join before presenting report... 21:02:17 INFO - com.welflex.zookeeper.Agent.joinBriefing(38) | Agent:005 joined Briefing:/M-debrief 21:02:17 INFO - com.welflex.zookeeper.Agent.joinBriefing(45) | Agent:005 waiting for other agents to join before ..... :17 INFO - com.welflex.zookeeper.Agent.joinBriefing(45) | Agent:005 waiting for other agents to join before presenting report... ...... 21:02:17 INFO - com.welflex.zookeeper.Agent.joinBriefing(45) | Agent:006 waiting for other agents to join before presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.joinBriefing(38) | Agent:007 joined Briefing:/M-debrief 21:02:18 INFO - com.welflex.zookeeper.Agent.joinBriefing(45) | Agent:007 waiting for other agents to join before presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(57) | Agent:002 presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(57) | Agent:005 presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(57) | Agent:007 presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(57) | Agent:003 presenting report... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(57) | Agent:001 presenting report... .... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:002 waiting for other agents to complete their briefings... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:002 waiting for other agents to complete their briefings... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(59) | Agent:000 completed report... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:000 waiting for other agents to complete their briefings... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:002 waiting for other agents to complete their briefings... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:000 waiting for other agents to complete their briefings... 21:02:18 INFO - com.welflex.zookeeper.Agent.presentReport(59) | Agent:007 completed report... 21:02:18 INFO - com.welflex.zookeeper.Agent.leaveBriefing(69) | Agent:007 waiting for other agents to complete their briefings... .... 21:02:19 INFO - com.welflex.zookeeper.Agent.leaveBriefing(78) | Agent:007 left briefing 21:02:19 INFO - com.welflex.zookeeper.Agent.leaveBriefing(78) | Agent:003 left briefing 21:02:19 INFO - com.welflex.zookeeper.Agent.leaveBriefing(78) | Agent:002 left briefing ... 21:02:19 INFO - com.welflex.zookeeper.Agent.leaveBriefing(78) | Agent:000 left briefing
Running the code:
Download a maven example of the above code from HERE. Execute a "mvn test" to see the example in action or import into eclipse to dissect the code. The example itself runs its tests on a single ZooKeeper server. There is no reason why the same cannot be expanded to try on a larger ZooKeeper ensemble.
Conclusion and Credits:
The examples shown are highly influenced by the examples provided at the ZooKeeper site. The code does not use the ZooKeeper code directly but instead uses a wrapper around the same, i.e., ZkClient, which provides a much easier experience to using ZooKeeper than the default ZooKeeper API. The examples also rely heavily on the excellent article and supporting code by Erez Mazor who utilizes Spring Framework very nicely to demonstrate Leader Election and control of the same. I simply loved his code and images and have used parts of the same in the above demonstration. I am sure I have only touched the surface of ZooKeeper and am hoping I can learn more about the same. If my understanding about any of the concepts mentioned above is flawed, I would love to hear about the same. Again, a very Happy 2012! Keep the faith, the world won't end on December 21'st.









