Introduction
Kubernetes is container orchestration and scaling system from google. It provides you the ability to deploy, scale and manage container based applications and provides mechanism such as service discovery, resource sizing, self healing etc. fabric8 is a platform for creating, deploying and scaling Microservices based of Kubernetes and Docker. As with all frameworks nowadays, it follows an 'opinionated' view around how it does these things. The platform also has support for Java Based (Spring Boot) micro services. OpenShift, the Hosted Container Platform by RedHat is based of fabric8. fabric8 promotes the concept of Micro 'Service teams' and independent CI/CD pipelines if required by providing Microservice supporting tools like Logging, Monitoring and Alerting as readily integrateable services.
 From Gogs (git), Jenkins (build/CI/CD pipeline) to ELK (Logging)/Graphana(Monitoring) you get them all as add ons. There are many other add-ons that are available apart from the ones mentioned.
From Gogs (git), Jenkins (build/CI/CD pipeline) to ELK (Logging)/Graphana(Monitoring) you get them all as add ons. There are many other add-ons that are available apart from the ones mentioned.
There is a very nice presentation on youtube around creating a Service using fabric8. This post looks at providing a similar tutorial by using the product-gateway example I had shared in a previous blog.
SetUp
For the sake of this example, I used Minikube version v0.20.0. and as my demo was done on a Mac, I used the xhyve driver as I found it the most resource friendly of the options available. The fabric8 version used was: 0.4.133. I first installed and started Minikube and ensured that everything was functional by issuing the following commands:
Also note that if your fabric8 console did not launch, you could also launch it by issuing the following command which will result the console being opened in a new window:
At this point, you should be presented with a view of the default team:
Creating a fabric8 Microservice
There are a few ways you can generate a fabric8 micro service using Spring Boot. The fabric8 console has an option to generate a project that pretty much does what Spring Initializer does. Following that wizard will take you to through completion of your service. In my case, I was porting existing product-gateway example over so I followed a slightly different route. I did the following for each of the services:
Run the following command on the base of your project:
From the root level of your project, issue the following:
At this point on the fabric8 console if you click on Team Dashboard, you should see your project listed.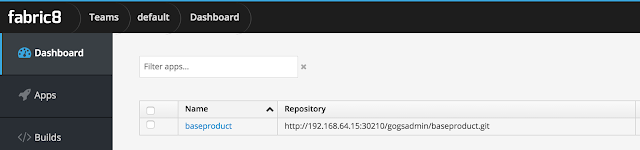
Click on the hyperlink showing the project to open the tab where you are asked to configure secrets.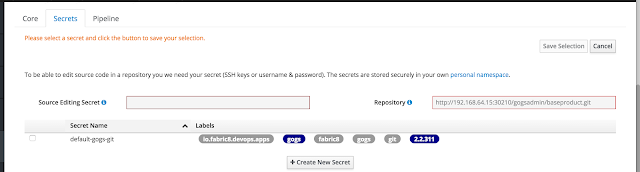
For the scope of this example select the default-gogs-git and click Save Selection on the top right. You will then be presented with a page that allows you to select the build pipeline for this project. Wait for a bit for this page to load.
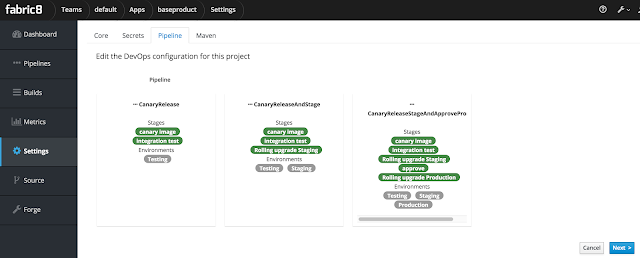
Select the last option with Canary test and click Next. The build should kick off and during the build process, you should be prompted to approve the next step to goto production, something like the below:
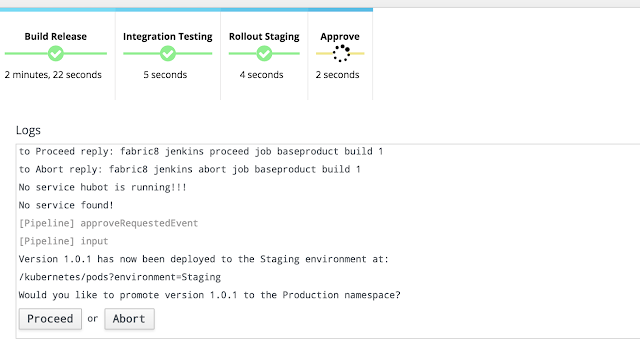
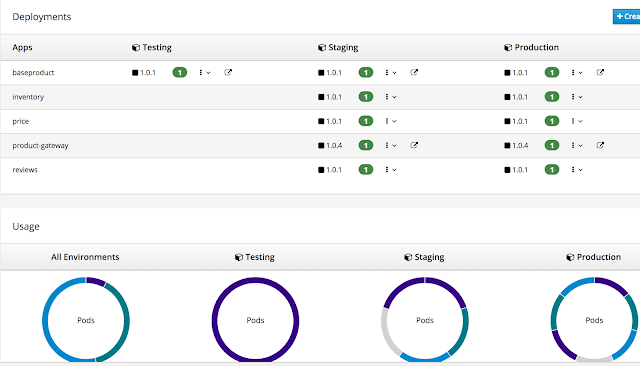
Once you select 'Proceed' your build will move to production. At this point what you have is a project out in production ready to received traffic. Once you import all the applications in the product-gateway example, you should a view like the below showing the deployments across environments:
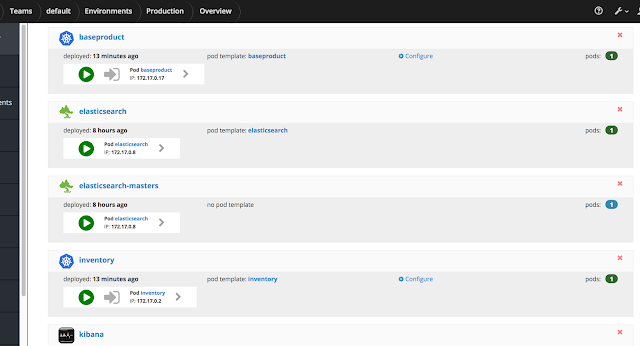
Your production environment should look something like the below showing your application and other supporting applications:
If your product-gateway application is deployed successfully, you should be able to open it up and access the product resource of the one product that the application supports at :
http://192.168.64.19:31067/product/9310301 The above call will result in the invoking of the base product, reviews, inventory and pricing services to provide a combined view of the product.
So how is the product-gateway discovering the base product and other services to invoke?
Kubernetes provides for service discovery natively using DNS or via Environment variables. For the sake of this example I used Enviroment variables but there is no reason you could not use the former. The following is the code snippet of the product-gateway showing the different configurations being injected:
Conclusion
The example should have given you an good start into of how dev pipe-lines could work with Kubernetes and containers and how fabric8's opinionated approach facilitates the same. The ability to push out immutable architectures using a Dev Ops pipeline like fabric8 is great for a team developing Microservices with Service Teams. I ran this on my laptop and must admit, it was not always smooth sailing. Seeing the forums around fabric8, the folk seem to be really responsive to the different issues surfaced. The documentation is quite extensive around the product as well. Kudos to the team behind it. I wish I had the time to install Chaos Monkey and the Chat support to see those Add-In's in action. I am also interested in understanding what Openshift software adds on top of fabric8 for their managed solution.. The code backing this example is available to clone from git hub.
Kubernetes is container orchestration and scaling system from google. It provides you the ability to deploy, scale and manage container based applications and provides mechanism such as service discovery, resource sizing, self healing etc. fabric8 is a platform for creating, deploying and scaling Microservices based of Kubernetes and Docker. As with all frameworks nowadays, it follows an 'opinionated' view around how it does these things. The platform also has support for Java Based (Spring Boot) micro services. OpenShift, the Hosted Container Platform by RedHat is based of fabric8. fabric8 promotes the concept of Micro 'Service teams' and independent CI/CD pipelines if required by providing Microservice supporting tools like Logging, Monitoring and Alerting as readily integrateable services.

There is a very nice presentation on youtube around creating a Service using fabric8. This post looks at providing a similar tutorial by using the product-gateway example I had shared in a previous blog.
SetUp
For the sake of this example, I used Minikube version v0.20.0. and as my demo was done on a Mac, I used the xhyve driver as I found it the most resource friendly of the options available. The fabric8 version used was: 0.4.133. I first installed and started Minikube and ensured that everything was functional by issuing the following commands:
>minkube status minikube: Running localkube: Running kubectl: Correctly Configured: pointing to minikube-vm at 192.168.64.19I then proceeded to install fabric8 by installing gofabric8. If for whatever reason the latest version of fabric8 does not work for you, you can try to install the version I used by going to the releases site. Start fabric8 by issuing the command
>gofabric8 startThe above will result in the downloading of a number of package and then result in the launching of the fabric8 console. Be patient as this takes some time. You could issue the following command on a different window to see the status of fabric8 set up:
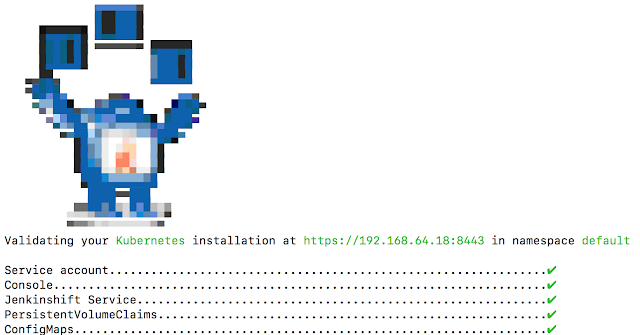
>kubectl get pods -w NAME READY STATUS RESTARTS AGE configmapcontroller-4273343753-2g03x 1/1 Running 2 6d exposecontroller-2031404732-lz7xs 1/1 Running 2 6d fabric8-3873669821-7gftx 2/2 Running 3 6d fabric8-docker-registry-125311296-pm0hq 1/1 Running 1 6d fabric8-forge-1088523184-3f5v4 1/1 Running 1 6d gogs-1594149129-wgsh3 1/1 Running 1 6d jenkins-56914896-x9t58 1/1 Running 2 6d nexus-2230784709-ccrdx 1/1 Running 2 6dOnce fabric8 has started successfully, you can also issue a command to validate fabric8 by issuing:
>gofabric8 validateIf all is good you should see something like the below:

Also note that if your fabric8 console did not launch, you could also launch it by issuing the following command which will result the console being opened in a new window:
>gofabric8 console
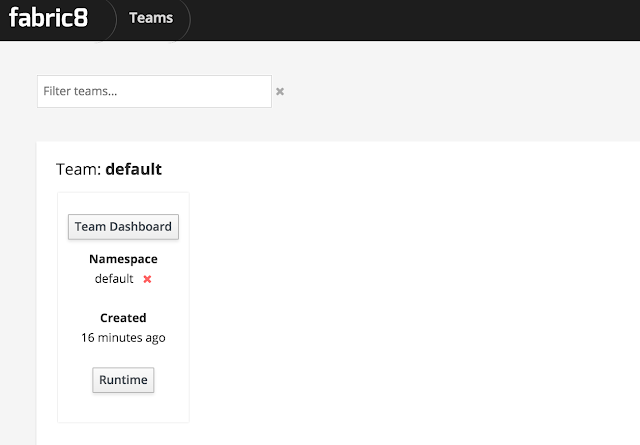
At this point, you should be presented with a view of the default team:

Creating a fabric8 Microservice
There are a few ways you can generate a fabric8 micro service using Spring Boot. The fabric8 console has an option to generate a project that pretty much does what Spring Initializer does. Following that wizard will take you to through completion of your service. In my case, I was porting existing product-gateway example over so I followed a slightly different route. I did the following for each of the services:
Setup Pom
Run the following command on the base of your project:
>mvn io.fabric8:fabric8-maven-plugin:3.5.19:setupThis will result in your pom being augmented with fabric8 plugin (f8-m-p). The plugin itself is primarily focussed on Building Docker images and creating Kubernetes resource descriptors. If you are simply using the provided product-gateway as an example, you don't need to run the setup step as it has been pre-configured with the necessary plugin.
Import Project
From the root level of your project, issue the following:
>mvn fabric8:importYou will be asked for the git user name and password. You can provide gogsadmin/RedHat$1. Your project should now be imported into fabric8. You can access the Gogs(git) repository from the fabric8 console or by issuing the following on the command line:
>gofabric8 service gogsYou can login using the same credentials mentioned above and see that your project has been imported into git.
Configuring your Build
At this point on the fabric8 console if you click on Team Dashboard, you should see your project listed.

Click on the hyperlink showing the project to open the tab where you are asked to configure secrets.

For the scope of this example select the default-gogs-git and click Save Selection on the top right. You will then be presented with a page that allows you to select the build pipeline for this project. Wait for a bit for this page to load.

Select the last option with Canary test and click Next. The build should kick off and during the build process, you should be prompted to approve the next step to goto production, something like the below:

Once you select 'Proceed' your build will move to production. At this point what you have is a project out in production ready to received traffic. Once you import all the applications in the product-gateway example, you should a view like the below showing the deployments across environments:

Your production environment should look something like the below showing your application and other supporting applications:

If your product-gateway application is deployed successfully, you should be able to open it up and access the product resource of the one product that the application supports at :
http://192.168.64.19:31067/product/9310301 The above call will result in the invoking of the base product, reviews, inventory and pricing services to provide a combined view of the product.
So how is the product-gateway discovering the base product and other services to invoke?
Kubernetes provides for service discovery natively using DNS or via Environment variables. For the sake of this example I used Enviroment variables but there is no reason you could not use the former. The following is the code snippet of the product-gateway showing the different configurations being injected:
@RestController
public class ProductResource {
@Value("${BASEPRODUCT_SERVICE_HOST:localhost}")
private String baseProductServiceHost;
@Value("${BASEPRODUCT_SERVICE_PORT:9090}")
private int baseProductServicePort;
@Value("${INVENTORY_SERVICE_HOST:localhost}")
private String inventoryServiceHost;
@Value("${INVENTORY_SERVICE_PORT:9091}")
private String inventoryServicePort;
@Value("${PRICE_SERVICE_HOST:localhost}")
private String priceServiceHost;
@Value("${PRICE_SERVICE_PORT:9094}")
private String priceServicePort;
@Value("${REVIEWS_SERVICE_HOST:localhost}")
private String reviewsServiceHost;
@Value("${REVIEWS_SERVICE_PORT:9093}")
private String reviewsServicePort;
@RequestMapping(value = "/product/{id}", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_VALUE)
@ResponseBody
.....
}
At this point what you have is a working pipe line. What about Logging, Monitoring etc etc. These are available for you as add-ons to your environment. For Logging, I went ahead and installed the Logging Template that put fluentd + ELK stack for searching through logs. You should then be able to search for events through Kibana.Conclusion
The example should have given you an good start into of how dev pipe-lines could work with Kubernetes and containers and how fabric8's opinionated approach facilitates the same. The ability to push out immutable architectures using a Dev Ops pipeline like fabric8 is great for a team developing Microservices with Service Teams. I ran this on my laptop and must admit, it was not always smooth sailing. Seeing the forums around fabric8, the folk seem to be really responsive to the different issues surfaced. The documentation is quite extensive around the product as well. Kudos to the team behind it. I wish I had the time to install Chaos Monkey and the Chat support to see those Add-In's in action. I am also interested in understanding what Openshift software adds on top of fabric8 for their managed solution.. The code backing this example is available to clone from git hub.






